This is a part of a series of blog posts on data access with Dapper. To see the full list of posts, visit the Dapper Series Index Page.
In today's post, we will start our journey into more complex query scenarios by exploring how to load related entities. There are a few different scenarios to cover here. In this post we will be covering the Many-to-One scenario.
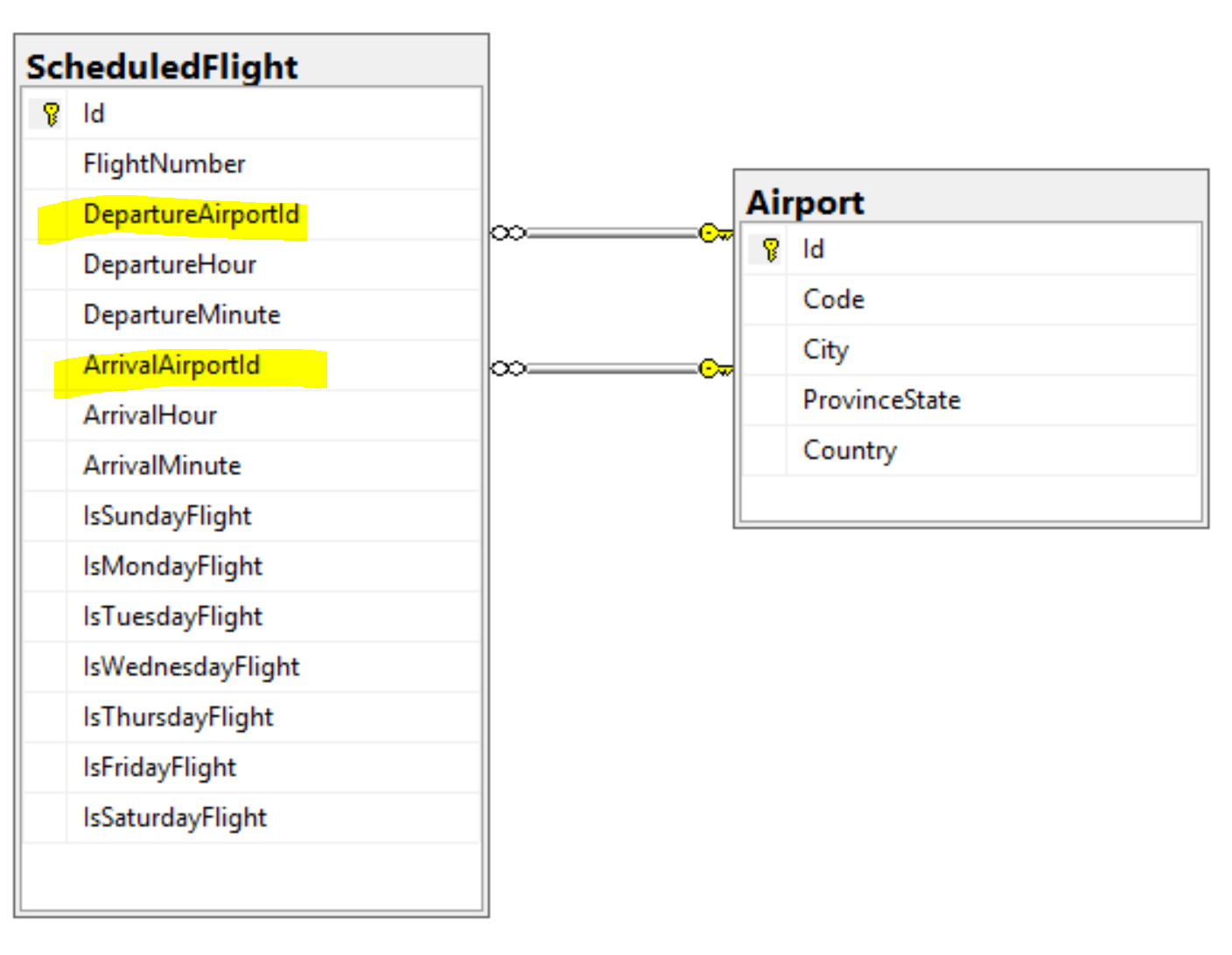
Continuing with our sample domain for the ever expanding Air Paquette airline, we will now look at loading a list of ScheduledFlight entities. A ScheduleFlight has a departure Airport and an arrival Airport.
1 | public class ScheduledFlight |
Side Note: Let's ignore my poor representation of the arrival and departure times of the scheduled flights. In a future most we might look using Noda Time to properly represent these values.
Loading everything in a single query
Using Dapper, we can easily load a list of ScheduledFlight using a single query. First, we need to craft a query that returns all the columns for a ScheduledFlight, the departure Airport and the arrival Airport in a single row.
1 | SELECT s.Id, s.FlightNumber, s.DepartureHour, s.DepartureMinute, s.ArrivalHour, s.ArrivalMinute, s.IsSundayFlight, s.IsMondayFlight, s.IsTuesdayFlight, s.IsWednesdayFlight, s.IsThursdayFlight, s.IsFridayFlight, s.IsSaturdayFlight, |
We use the QueryAsync method to load a list of ScheduledFlight entities along with their related DepartureAirport and ArrivalAirport entities. The parameters we pass in are a little different from what we saw in our previous posts.
1 | [] |
First, instead of a single type parameter <ScheduledFlight>, we need to provide a series of type parameters: <ScheduledFlight, Airport, Airport, ScheduledFlight>. The first 3 parameters specify the types that are contained in each row that the query returns. In this example, each row contains columns that will be mapped to ScheduledFlight and 2 Airports. The order matters here, and Dapper assumes that when it seems a column named Id then it is looking at columns for the next entity type. In the example below, the columns from Id to IsSaturdayFlight are mapped to a ScheduledFlight entity. The next 5 columns Id, Code, City, ProvinceState, Country are mapped to an Airport entity, and the last 5 columns are mapped to a second Airport entity. If you aren't using Id, you can use the optional splitOn argument to specify the column names that Dapper should use to identity the start of each entity type.
What's that last type parameter? Why do we need to specify ScheduledFlight again? Well, I'm glad you asked. The thing about Dapper is that it doesn't actually know much about the structure of our entities so we need to tell it how to wire up the 3 entities that it just mapped from a row. That last ScheduledFlight type parameter is telling Dapper that ScheduledFlight is ultimately the entity we want to return from this query. It is important for the second argument that is passed to the QueryAsync method.
That second argument is a function that takes in the 3 entities that were mapped back from that row and returns and entity of the type that was specified as the last type parameter. In this case, we assign the first Airport to the flight's DepartureAirport property and assign the second Airport to the flight's ArrivalAiport parameter, then we return the flight that was passed in.
1 | (flight, departure, arrival ) => { |
The first argument argument passed to the QueryAsync method is the SQL query, and the third argument is an anonymous object containing any parameters for that query. Those arguments are really no different than the simple examples we saw in previous blog posts.
Wrapping it up
Dapper refers to this technique as Multi Mapping. I think it's called that because we are mapping multiple entities from each row that the query returns. In a fully featured ORM like Entity Framework, we call this feature Eager Loading. It is an optimization technique that avoids the need for multiple queries in order to load an entity and it's associated entities.
This approach is simple enough to use and it does reduce the number of round trips needed to load a set of entities. It does, however, come at a cost. Specifically, the results of the query end up causing some duplication of data. As you can see below, the data for the Calgary and Vancouver airports is repeated in each row.

This isn't a huge problem if the result set only contains 3 rows but it can become problematic when dealing with large result sets. In addition to creating somewhat bloated result sets, Dapper will also create new instances of those related entities for each row in the result set. In the example above, we would end up with 3 instances of the Airport class representing YYC - Calgary and 3 instances of the Airport class representing YVR - Vancouver. Again, this isn't necessarily a big problem when we have 3 rows in the result set but with larger result sets it could cause your application to use a lot more memory than necessary.
It is worth considering the cost associated with this approach. Given the added memory cost, this approach might be better suited to One-to-One associations rather than the Many-to-One example we talked about in this post. In the next post, we will explore an alternate approach that is more memory efficient but probably a little more costly on the CPU for the mapping.
